深層強化学習エージェントの判断根拠に関する解析
高い制御性能を獲得可能な技術として,深層強化学習が注目されています.深層強化学習は,環境とエージェントのインタラクションを通じて,エージェントモデルの最適な振る舞いを学習できます.
複雑な制御が必要となるビデオゲームにおける高いスコアの達成や,自律移動ロボットにおける柔軟な行動計画の獲得など,深層強化学習を対象とした研究として数多く報告されています.しかし,学習によって獲得したエージェントモデルの振る舞いに対する意思決定過程,すなわちどのような根拠にもとづいて行動を選択したかを,ユーザである私たちが理解することは困難です.
高い制御性能を保有する深層強化学習エージェントモデルを,さまざまな要因が複雑に絡み合う実環境において,ブラックボックスのまま扱うのはリスクが伴います.これらの背景から,私たちは深層強化学習エージェントモデルの判断根拠を分析する研究に取り組んでいます.
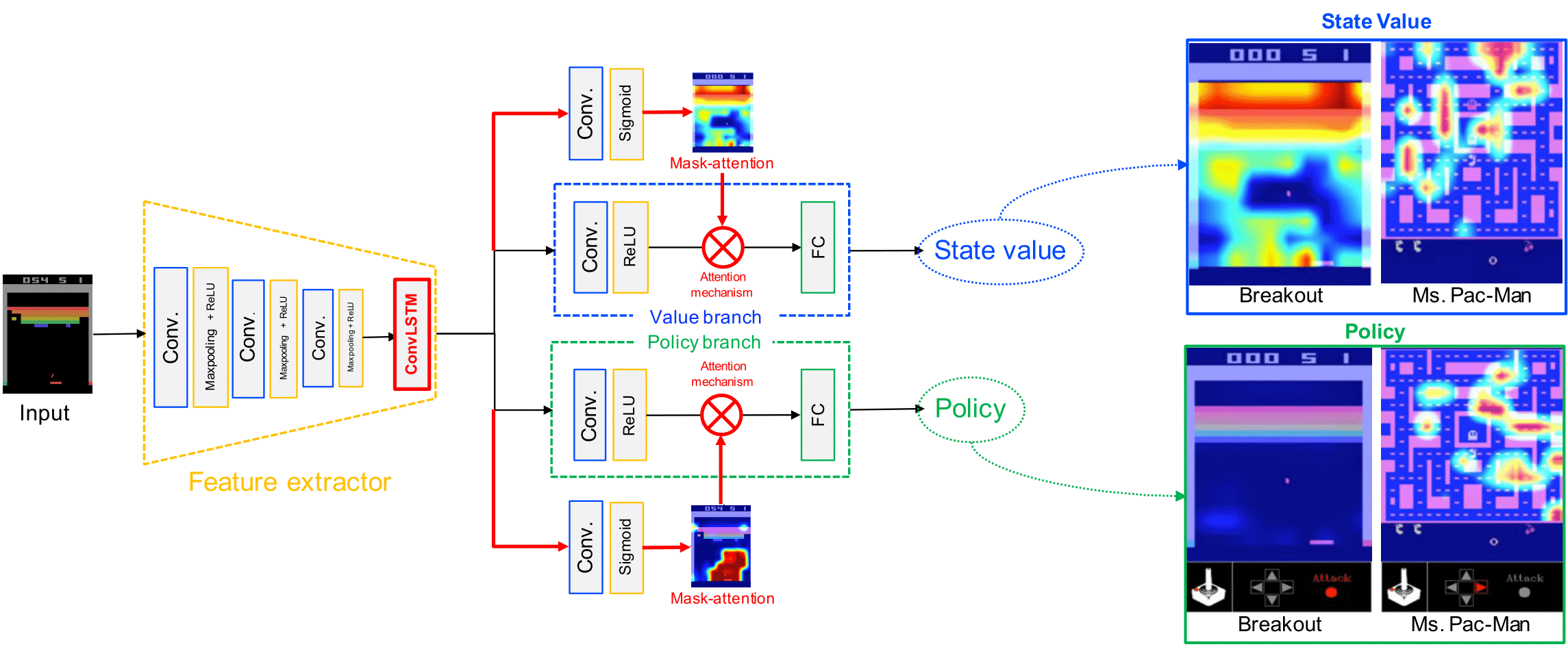
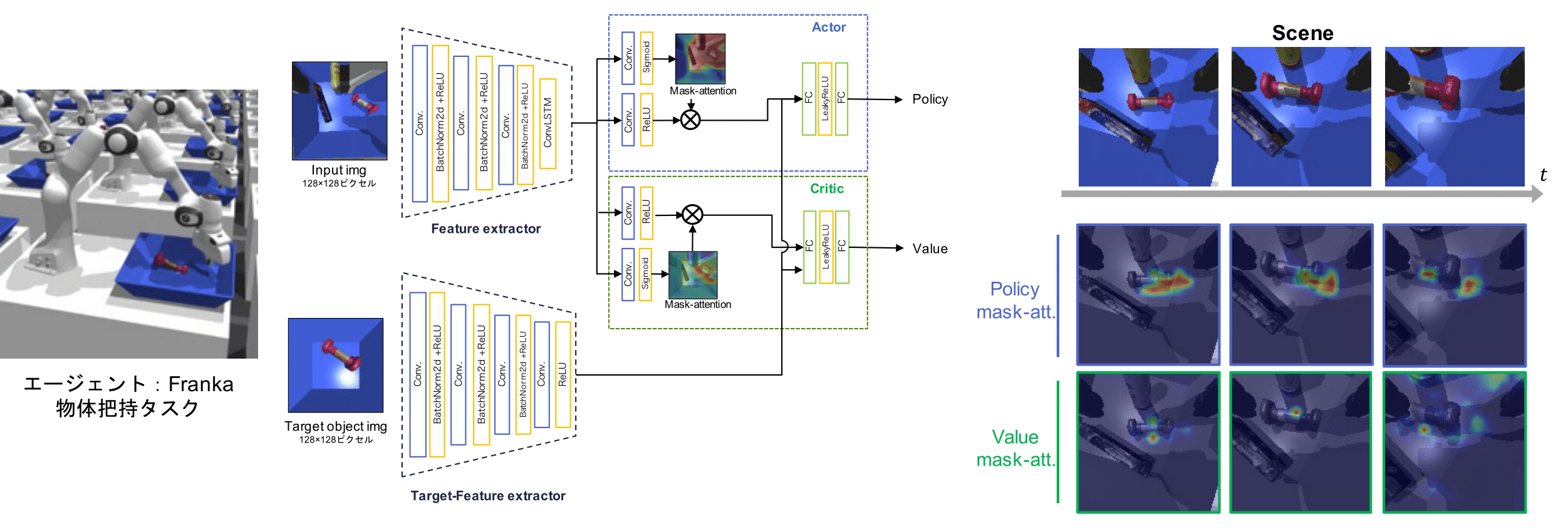
Mask-Attention A3C
従来のActor-Criticベースな深層強化学習手法では,方策(エージェントの行動指針)と状態価値(現状態の良さ)を学習することで,エージェントモデルによる最適な振る舞いを実現しています.本研究は,このエージェントモデルの方策と状態価値に着目し,エージェントモデルの意思決定過程を分析する視覚的説明手法 Mask-Attention A3C (Mask A3C) を提案しています.エージェントモデルの出力ブランチ (方策.状態価値) に Attetion 機構を統合し,mask-attentionを用いたマスク処理を行います.
これにより,方策および状態価値の2つの観点からエージェントモデルの判断根拠をヒートマップとして可視化します.
ビデオゲームおよびロボットマニピュレーションを対象とした実験から,方策と状態価値の2つの異なる視点からエージェントモデルの意思決定を分析可能であることを確認しました.
Action Q-Transformer
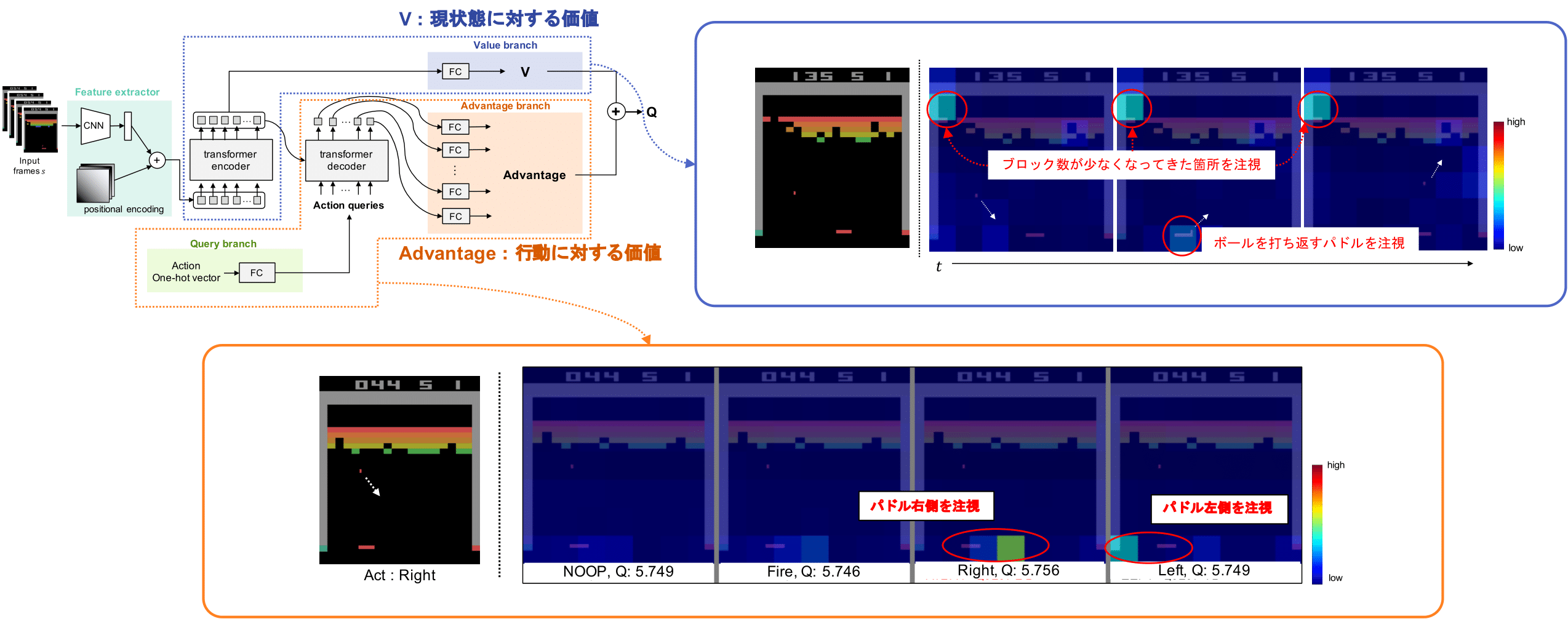
従来の深層強化学習における視覚的説明手法は,エージェントモデルが選択した特定の行動について,その行動に対する判断根拠を分析してきました.しかし,エージェントモデルの意思決定過程を包括的に理解するには,特定の行動だけでなく,エージェントモデルが選択可能な全ての行動を対象に解析する必要があります.
本研究では,エージェントが選択可能な全ての行動を網羅的に解析するため,行動情報をクエリとして用いる Transformer Encoder-Decoder 構造を導入した視覚的説明手法 Action Q-Transformer (AQT) を提案します.Decoder 部では,各行動をクエリとして表現した action query を用いることで,行動ごとに固有のアテンションを算出します.これにより,特定の action query を用いることで,任意の行動に対するエージェントモデルのアテンションを算出可能としました.エージェントモデルの行動選択に寄与する全ての行動に対するアテンションを可視化することで,解釈性の高いエージェントモデルを実現しました.
ビデオゲームおよび屋内環境におけるロボット制御タスクを対象とした実験から,エージェントモデルの意思決定過程を詳細に分析できることを確認しました.
また,ロボット制御のような実環境でエージェントが動作するタスクにおいて,エージェントモデルの意思決定をアテンションマップとして提供する方法では,マップと物理空間が直接的に対応づけられません.そのため,実環境で動作するロボットエージェントについて,ユーザがロボットエージェントの行動を直感的に理解しにくいという課題があります.そこで,拡張現実感(AR)を用いてアテンションマップを物理空間上に投影する視覚的フィードバック手法を提案します.
ロボット制御タスクに対するユーザ評価により,ARを用いた視覚フィードバックの有効性を確認しました.
マルチエージェント強化学習における視覚的説明
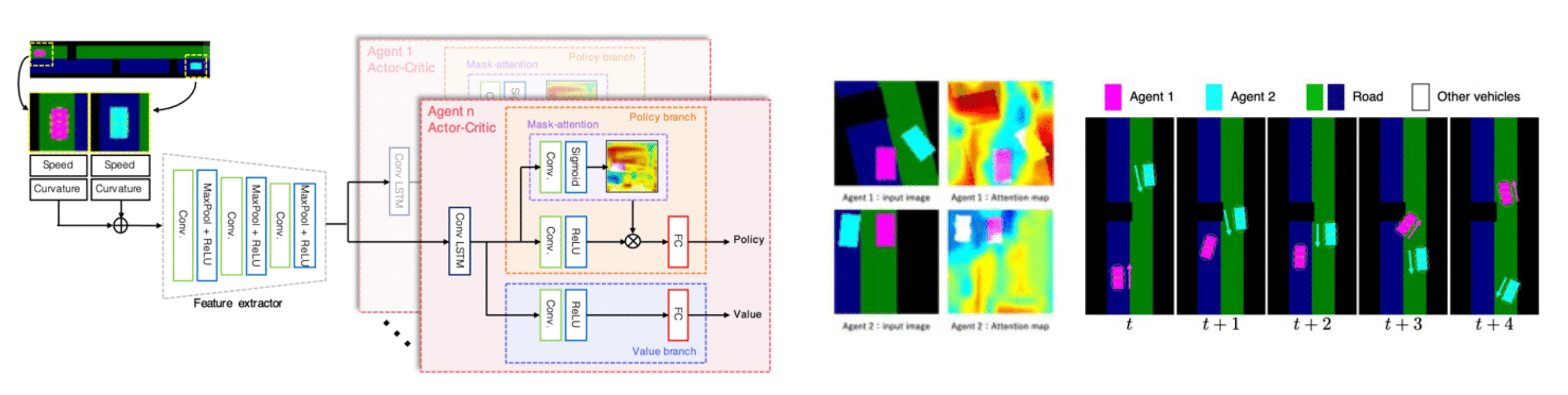
マルチエージェント強化学習は,同一環境に存在する複数のエージェントを共通目標をもとに学習させることで,エージェント間の協調行動を獲得可能な技術です.そのため,交通環境における信号制御や多腕ロボットの制御など,実環境における複雑なタスクへの応用が期待されています.
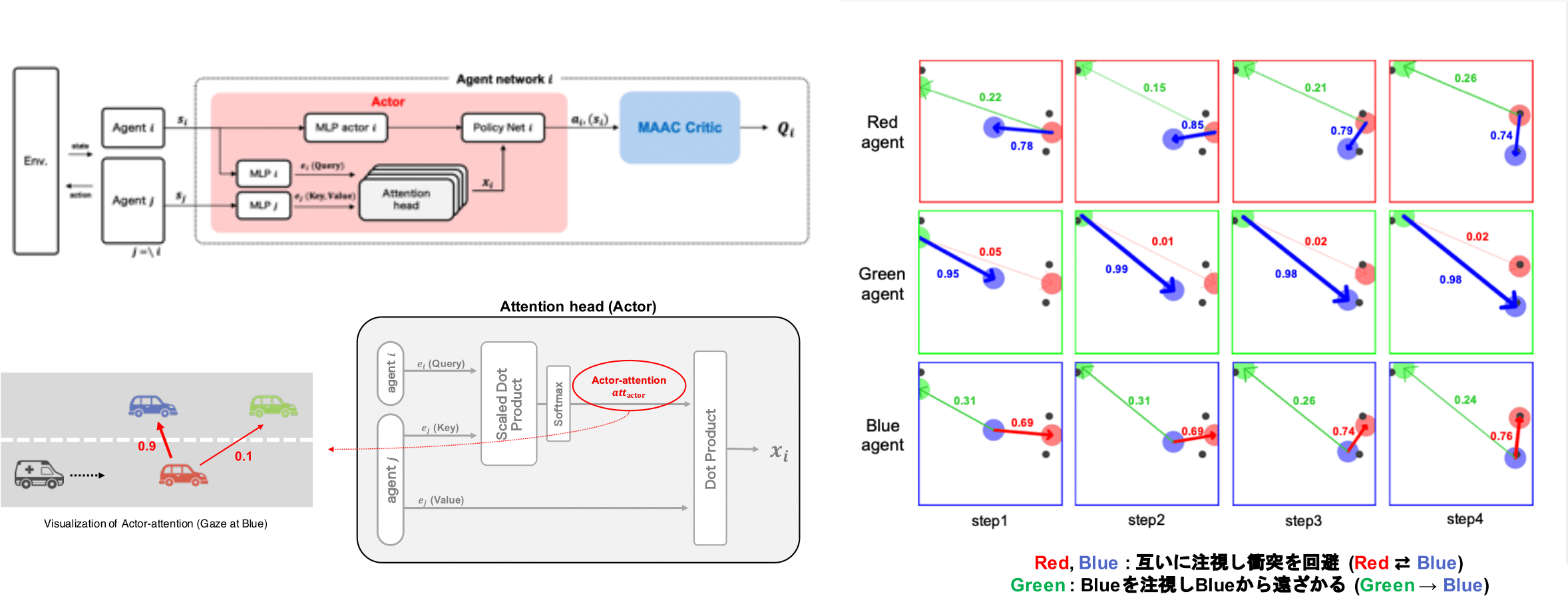
本研究では,Actor-Critic 法を用いた Multi-Agent Actor-Critic (MAAC) をベースとし,エージェントモデルの行動を決定する Actor へ Attention-head を導入します.MAAC における Critic が全エージェント間で,Attention head を共有するのとは対照的に,本手法における Actor の Attention-head はエージェントごとに独立に構築します.これにより,Actor の Attention-head は,Actor-attention(各エージェントがどの他のエージェントを注視しているか)を算出し,協調行動に対する解釈の提供を実現しました.
協調タスクを扱うマルチエージェント環境を対象とした評価実験から,複数エージェント間の協調行動に対する判断根拠を容易に分析可能であることを確認しました.
自律走行システムの動作計画は,車両とその周囲の情報を観測し,ルールベースに基づいて軌跡を計画しています.しかし,信号機のない交差点で2台の車両がすれ違うような複雑なシーンでは,複雑なルールが必要となり,ルールベースでの対応では限界があります.このような複雑なシーンにおける複数車両の協調動作の実現において,マルチエージェント深層強化学習が注目されています.
本研究では,このようなデッドロックが生じるシーンを対象とし,マルチエージェント強化学習における視覚的説明手法を提案します.提案手法は,単一の Feauture extractor と Actor-Critic ブランチから構成し,mask-attention 機構を導入します.
アテンションマップを可視化することで,デッドロックシーンにおいて協調動作するエージェントモデルの判断根拠の解析を実現しました.
自律走行シミュレータ環境を対象とした実験から,提案手法がデッドロックを回避する動作を獲得し,アテンションマップから協調行動に対する判断根拠を分析可能であることを確認しました.