ビジョン技術を用いたロボットへの応用
VisionRobotics from MPRG, Chubu University on Vimeo.
近年,画像を用いた物体認識技術は目覚しい成長を遂げており,認識精度が飛躍的に向上しています.このビジョン技術はロボットへ組み込むことが可能です.我々の研究では,ロボットの制御に必要な画像認識技術の研究や,画像認識結果を与えてロボットを制御する研究に取り組んでいます.
Deep Convolutional Neural Networkによる把持位置検出
産業用ロボットや生活支援ロボットの重要なタスクとして,工業部品や日用品などの物体を正確に把持する(掴む)ことが挙げられます.このピッキングタスクを実現するには,ロボットに搭載されているカメラセンサを用いて物体の画像を撮影し,その物体の最適な把持位置を検出する必要があります.我々の研究では,Deep Convolutional Neural Networkの学習過程に把持可能性(Graspability)を導入することで,高精度な物体の把持位置検出法を実現します.実験の結果,従来の物体把持位置検出法と比べて約22.8%性能が向上していることが確認できます.また,本手法は10fpsで把持位置を検出することが可能です.

Multi-task DSSDによる
物体位置と物体把持位置の同時推定
物流倉庫や生活空間で稼働するロボットには,多品種の物体から特定の物体を探して把持する機能が望まれます.深層学習を用いた物体検出アルゴリズムであるDeconvolutional Single Shot Detector (DSSD) をベースとして,物体検出・セマンティックセグメンテーション・物体把持位置検出の3タスクを同時実行するMulti-task DSSD (MT-DSSD) を提案します.DSSDから得られるマルチスケールの特徴マップに対して,従来の物体検出だけでなくセマンティックセグメンテーションを行うサブネットワーク (ブランチ) および把持位置検出と当該把持位置の把持しやすさを推定するブランチを追加しました.また,3タスクを同時に学習することで,各タスクの精度が向上する効果も確認できました.提案手法を実際のロボットシステムに組み込んだ結果,Amazon Robotics Challenge競技用アイテムのほとんどを8割以上の精度で把持できました.MT-DSSDの推定は300ミリ秒程度であり,把持動作のボトルネックになることはありません.

クラウド型画像解析エンジンにおけるDCNNの自動分割
少子高齢社会の到来によって、生活支援ロボットの研究開発が精力的に進められています.一般にロボットの計算リソースは限られているため,認識エンジンなど計算コストの高い処理を,クラウド上のコンピュータ行うクラウドロボティクスという概念への関心が高まっています.一般的なクラウド型の画像認識エンジンでは,ロボットが撮影した画像をクラウド上の認識エンジンにそのまま送信しますが,実際の運用のためには,プライバシーの配慮や,通信状況の配慮が必要となります.そこで我々はDeep Convolutional Neural Networkの処理をロボットとクラウドサーバで分割して処理するシステムを提案します.分割した特徴マップをクラウドサーバに送信するシステムを構築することで,Deep Convolutional Neural Networkの処理の一部をクラウドサーバー側で担うことが可能です.分割する層は,要求レイテンシと要求精度を満たすように自動決定します.また,送受信する特徴マップは個人を特定できる情報が削られているため,プライバシーに配慮することができます.
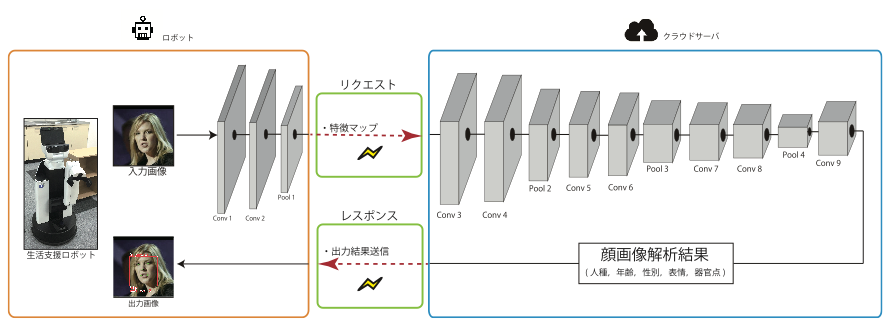
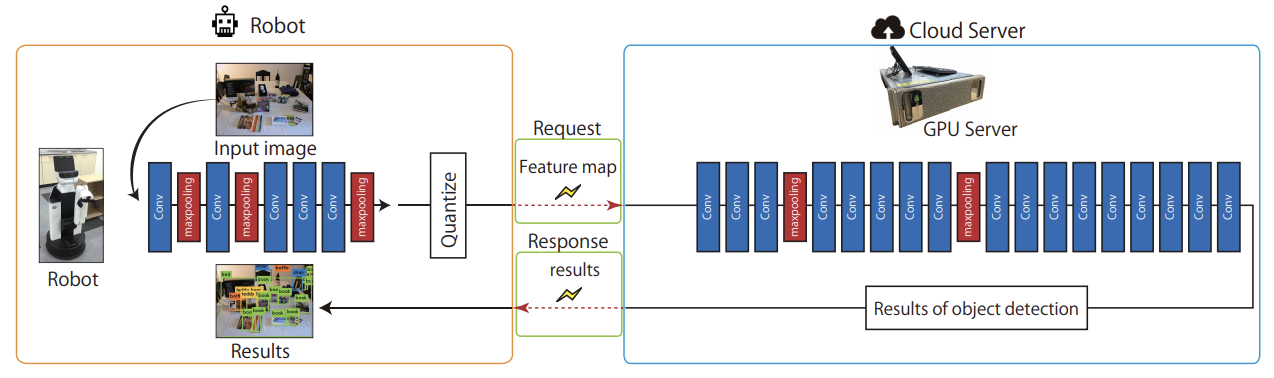
上記のクラウド型画像解析エンジンは,物体検出問題にも適用できます.物体検出を行うCNNのひとつであるYOLO v2は,畳み込み層およびプーリング層が27層あり,入力層に近い層で分割すると,通信時間が長くなる傾向があります.これは,CNNに入力する画像の解像度が高く,ロボット側のCNNから出力される特徴マップのデータ量が大きいことが原因です.そのため,通信時は特徴マップを量子化してサイズを圧縮します.量子化には,入力サンプルを等間隔に一定の量子化ステップ幅で近似する線形量子化,対数や任意の確率密度分布で変化させた量子化ステップ幅で近似する非線形量子化があります.量子化方法と量子化ステップ幅は,CNNの分割層と同様に自動的に決定し,要求レイテンシと要求精度を満たしつつクラウドサーバの計算量を最低限に抑えられます.
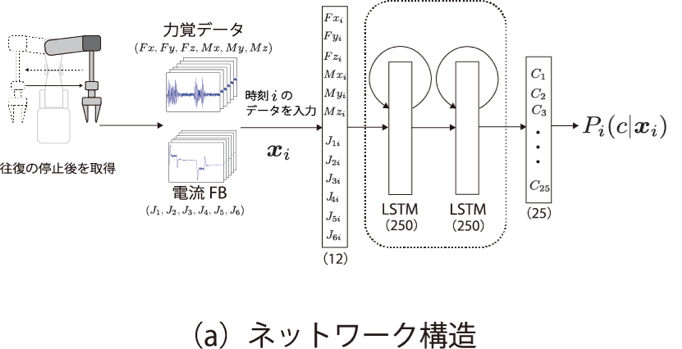
力覚センサを用いた把持物体の識別
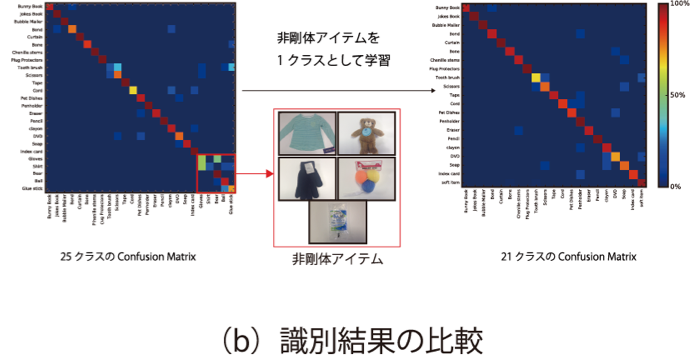
ビジョンセンサで取得した画像で物体識別をする場合,Deep Convolutional Neural Network等の機械学習を用いた方法により物体を識別します.しかし,画像からの視覚的な情報のみでは,箱の内包物の種類や量などを取得することができません.そこで我々は画像を用いずに,ロボットハンドに装着された力覚センサからの情報を用いて把持物体の識別を行いました.時系列状の力覚センサの値を取り扱うために,Long Short Term Memory (LSTM)を用います.非剛体の物体は形状の変化が生じやすいため,物体をXYZ方向に振った直後のセンサー値を用います.25クラスの物体識別にて79.7%の性能を実現しました.また,電流Feed Backの値を力覚センサの値を併用することで識別率が85.3%に向上し,非剛体のアイテム5クラスを1つのクラスとして学習すると、90.1%まで性能が向上しました.