物体検出モデルの評価と判断根拠の可視化
経産省のプロジェクトで利用されるシミュレータは,様々な時間帯,天候,対向車の種類などの諸条件を変えたデータセットを作成可能である.我々の研究では,シミュレータで作成した多種多様なデータを用いて,物体検出モデルの評価を行う.
物体検出モデルの精度比較
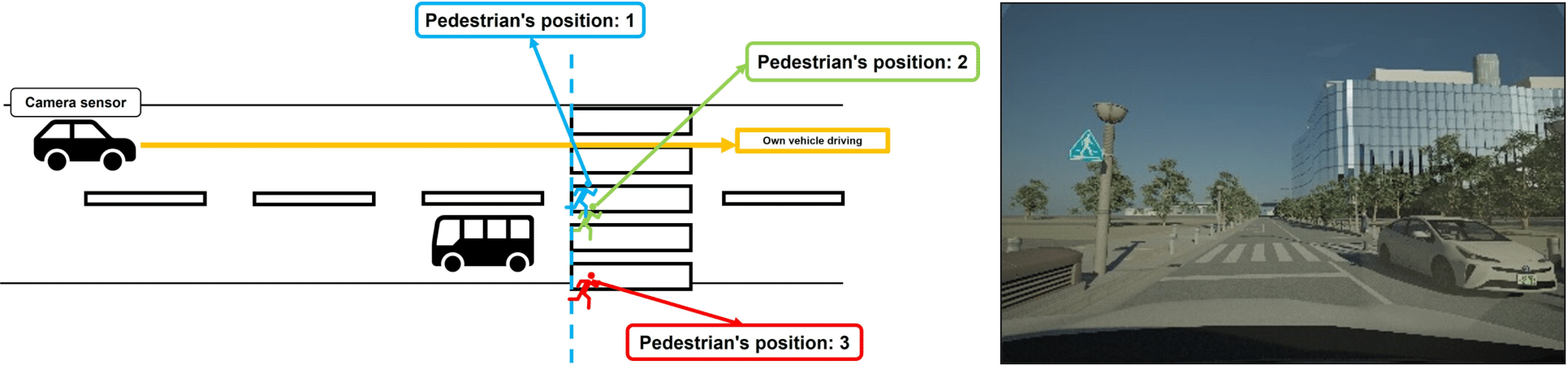
自動運転分野では,実環境で収集されたデータセットはコストが高く,エッジケースが少ないため,シミュレータを活用した評価が注目されている.本研究では、車載カメラによる歩行者検出を対象に,DIVPシミュレータで作成したデータを用いて,YOLOv5・YOLOv8・DETR・Faster R-CNNの4モデルを比較した.
距離15-23m間における歩行者検出精度の比較実験を行うと,YOLOv5とYOLOv8の検出精度が向上し,遮蔽率約70%ではYOLOv5の検出精度が向上していた.一方,子供の検出ではYOLOv5が他モデルより低く,子供が停車車両に遮蔽していないシーンにおいても子供を検出できていないことが確認できた.
遮蔽率65-75%間における歩行者検出精度の比較実験では,子供以外の検出精度が向上し,曇天や特定の歩行者(成人男性・ベビーカーを押す女性)では特にYOLOv5の検出精度が他の物体検出モデルと比較し,著しく高いことが確認できた.
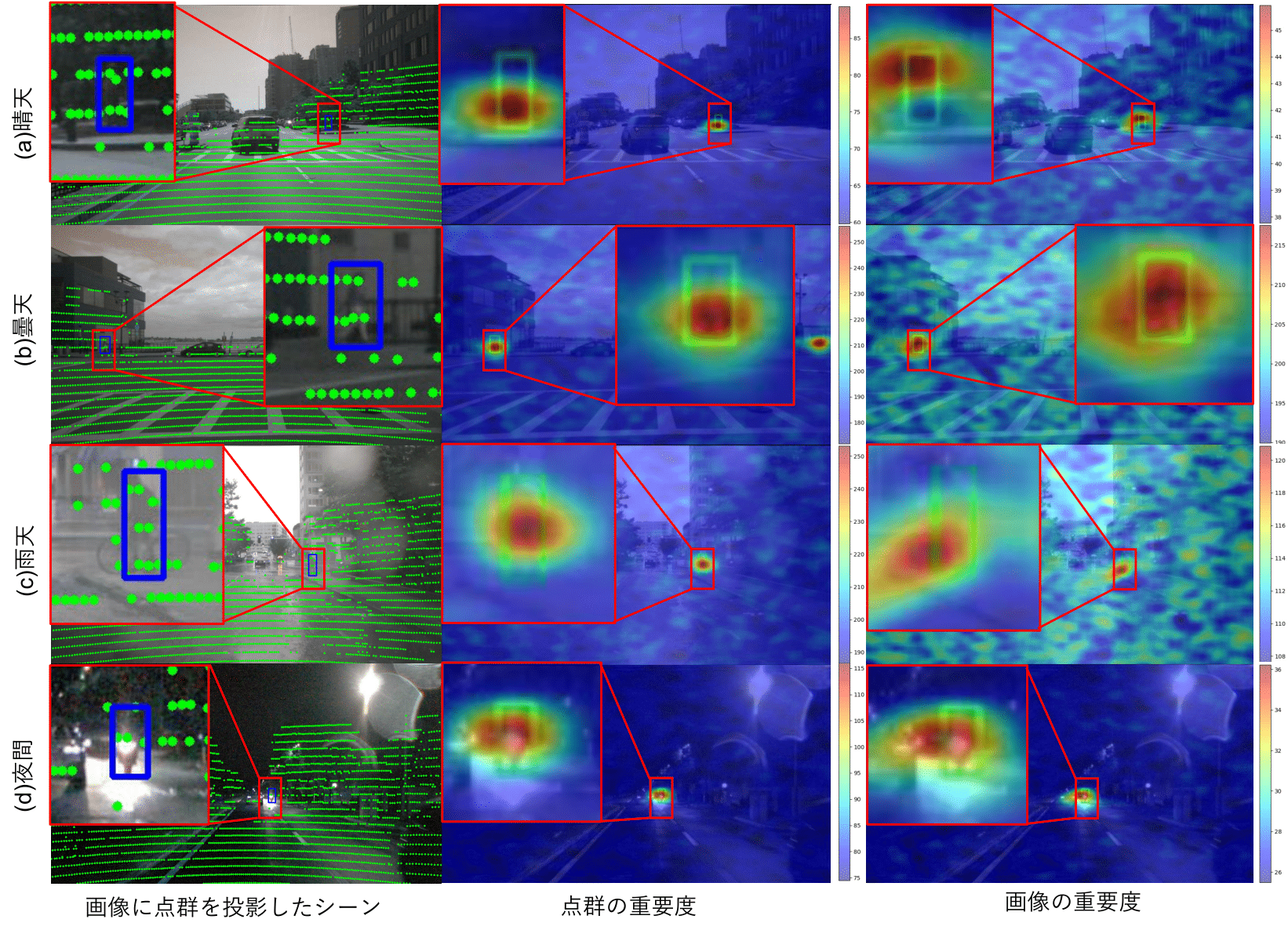
物体認識モデルの判断根拠の可視化
従来の物体認識モデルの判断根拠を可視化する手法は,画像を用いた認識モデルを対象としており,マルチモーダル手法には適した手法は存在しない.
本研究の目的は,画像と点群データを用いたマルチモーダル手法であるBEVFusionの検出結果に対する,各モダリティの重要度を可視化することである.そこで,モデルの内部構造に依存せず,汎用的に使用可能な摂動ベースの手法によっ
て重要度を可視化する.これにより,BEVFusionにおいては,重要な点群データは車両の点群が集中する箇所に多く,点群データが欠損している領域を画像情報によって補っていることが確認できた.