Attention mapを介した人の知見の導入
Transformerにおける人の知見の導入
高い認識性能を獲得可能な深層学習モデルとして,Transformerが注目されています.
Transformerは入力特徴の類似度を用いるAttention機構により空間特徴を学習します.
この機構により,TransformerはCNNより少ない層数で複雑な処理が可能となる.
しかし,従来のCNNベースの手法で用いられていた,深層学習モデルへの人の知見の導入についての研究がされていません.
このような背景から,私たちはTransformerにおける人の知見の導入を行う研究に取り組んでいます.
Reactive BiasによるViTへの人の知見の導入
Transformerモデルを画像認識タスクに適用した手法としてVision Transformer (ViT) が提案されています.
ViTは画像認識タスクにおいてCNNベースのモデルより高い性能を発揮してきました.
しかし,Transformerモデルにおける特徴抽出では,Attention機構を用いた処理であるMulti-Head Self Attentionを用いるため,人の知見は各層・各headにおけるSelf AttentionのバイアスとAttention機構を用いる事による入力への反応性に対応可能な形で導入する必要があります.
本研究では,ViTへの人の知見の導入を行うため,ViTのMulti-Head Self Attentionへ人の知見を導入するためのモジュールReative Biasを提案します.
Reactive Biasは,各Self Attentionのバイアスを学習するLearnable BiasとSelf Attentionの反応性に対応するReactive modeによって構成されます.
Reactive Biasを用いたViTへ人の知見の導入により,ViTと比較して分類精度および視覚的説明性の向上に有効である事を確認しました.
Attention mapを介した人の知見の導入(動画版)
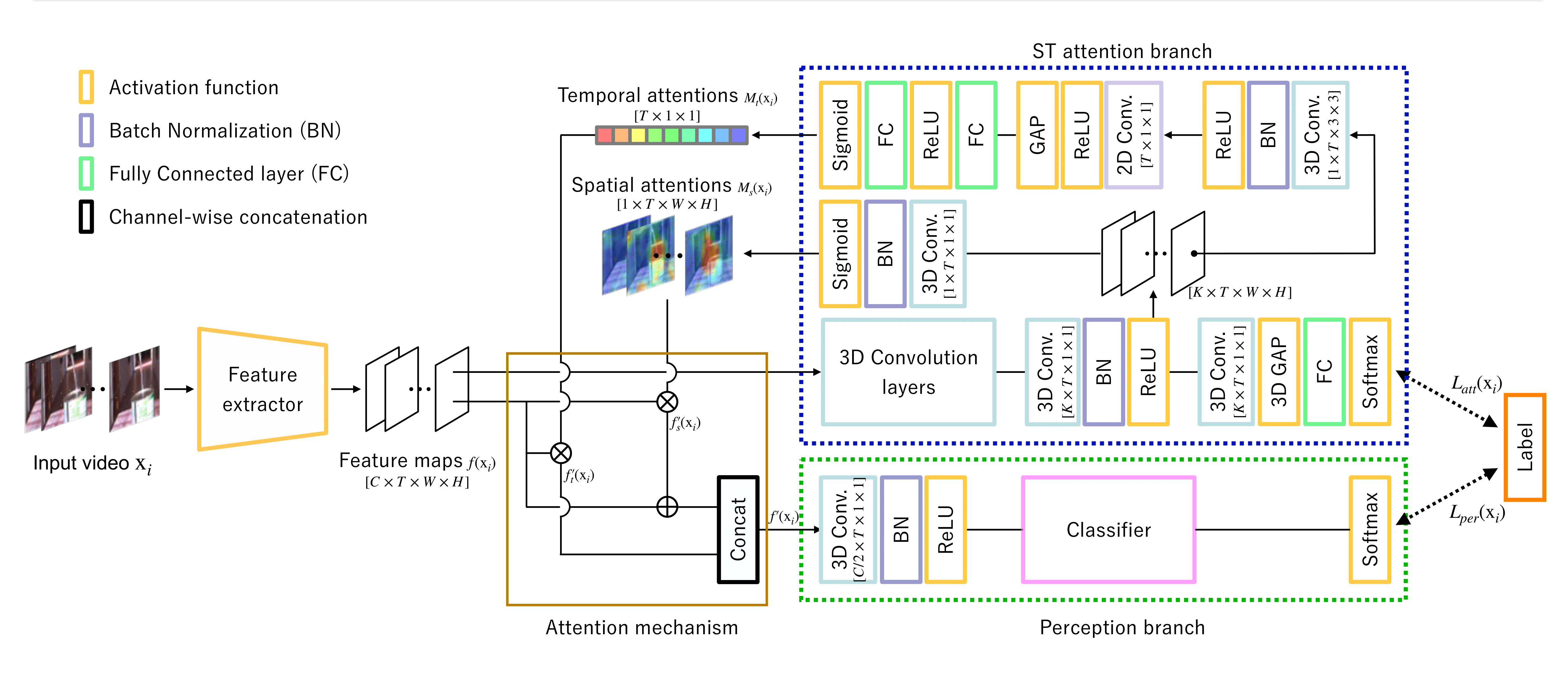
Spatio-Temporal Attention Branch Network
画像認識分野における視覚的説明では,深層学習が認識する際に注視した領域をヒートマップで表現した Attention map を解析します.
一方,動画像認識は静止画像とは異なり,空間情報だけでなく時間情報も考慮する必要があることから,判断根拠の解析が困難とされています.
そこで,本研究では画像認識分野における視覚的説明を動画像認識に拡張した Spatio-Temporal Attention Branch Network (ST-ABN) を提案します.
提案手法では,推論時の空間情報と時間情報に対する注視領域を獲得し Attention 機構へ応用することで,時間情報を同時に考慮した視覚的説明が可能となります.
Attention mapを介した人の知見の導入
動画像認識においても画像認識分野と同様の理由から,好ましい認識結果が獲得できない場合があります.
画像認識分野では人の知見を導入することでモデルの注視領域が改善し,認識精度が向上することが知られている一方,動画像認識分野では人の知見の導入に関する研究がされていません.
画像認識分野での研究により,空間情報に関するモデルの注視領域への人の知見導入の有効性は確認されていることから,提案手法では時間情報に関する注視領域 (Temporal Attention) を介して人の知見を導入します.
このとき出力された Temporal Attention と手動で修正した Temporal Attention から誤差を算出し, ST-ABNをファインチューニングします.
評価実験では, 認識精度の改善を確認し, より明確な注視領域の獲得を実現しました.
