human-like guidance
自動運転技術や高度運転支援システムの発展に伴い,車両が運転手に対して適切な情報を提供することの重要性が高まっています.
一般的に普及しているナビゲーションシステムは,地図情報に基づいた経路案内や,あらかじめ定められたフレーズによる音声案内が主となっています.
しかし,これらは運転手の直感的な理解を必ずしも促進するものではありません.
特に,走行環境の複雑さや動的な変化を考慮した情報提供が求められる場面において,従来の方法では十分な支援が困難となっています.
このような課題に対し,Human-like Guidanceに関する研究が注目されています.
Human-like Guidanceとは,車両周辺の状況をもとに,運転手にわかりやすくナビゲーションする技術を指します.
単にあらかじめ用意した定型文による案内ではなく人間が行うような自然な説明を通じて,運転手が適切な運転判断を下せることを目的としています.
我々の研究では,このHuman-like Guidanceの実現に向けた研究に取り組んでいます.
時空間シーングラフによる案内文生成
Human-like Guidanceの実現においては,自動車に搭載されるカメラから撮影された画像から,Image Captioningのような技術を用いて
ナビゲーション文章を生成するアプローチが考えられます.
しかし,このような手法の多くは,走行シーンのような多数のオブジェクトが含まれる画像の認識は困難であり,
特に時系列を持つ場合は不要な特徴が増加するためナビゲーションが安定しない可能性が挙げられます.
本研究では,オブジェクトの関係性に着目するため,画像内のオブジェクトを時空間シーングラフとして表現するアプローチを導入し,
グラフ入力に対応した文章生成モデルを用いることでナビゲーション文章を生成する手法を提案します.
これにより,車両周辺のオブジェクトの位置関係や動作の変化といった特徴を考慮することが可能となります.
評価実験の結果,提案手法はオブジェクトの動作を考慮した詳細な説明が可能であり,従来手法と比較して精度が向上したことを確認しました.

ドライバの視線情報を用いた案内分生成
Human-like Guidanceの目的は,ドライバが直感的に理解出来る案内文章を提供することです.
そこで,本研究ではドライバの視線情報を活用し,注視物体を用いることで直感的に理解出来る案内文章の生成を実現します.
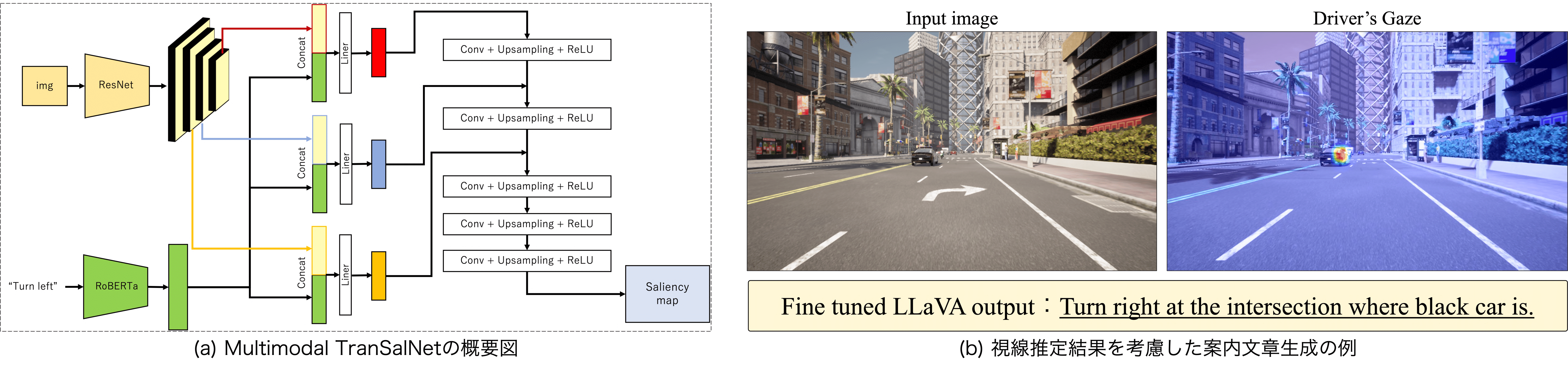
しかし,通常の車両にはドライバの視線を計測する機器は存在しないため,本研究ではドライバの視線を学習した視線推定モデルを構築する.さらに,視線推定結果を活用した案内文章生成モデル構築する.
本研究では,視線推定モデルを用いたHuman-like Guidance実現為に,データセット,視線推定モデル,案内文章生成モデルを提案します.
データセットでは,自動運転シミュレータであるCARLAで走行シーンを作成し,ディスプレイベースの視線計測機器でドライバの視線情報を収集した.案内文章データには,GPT-4oを活用した自動で案内文章データを生成するフレームワークを提案し,データセットを構築します.
視線推定モデルでは,ドライバの視線情報は進行方向によって変化することから,静止画に対する視線推定モデルであるTranSalNetをベースとし,進行方向を言語入力として加えたMultimodal TranSalNetを提案しました.
進行方向を言語入力として加えることで,進行方向を考慮した視線推定が可能となります.
案内文章生成では,様々なタスクで高い精度を発揮したオープンソースのLLaVAを,作成したデータセットでLoRAチューニングすることで暗黙的に視線情報を学習させ,視線情報を考慮した案内文章生成を実現しました.