近似計算を導入した線形識別器の早期判定による高速な識別
ラスタスキャンベースの物体検出では、膨大な数の検出ウィンドウから抽出した特徴量を識別器に入力して、検出対象か非検出対象に判別します。1枚の入力画像から網羅的にスキャンした検出ウィンドウは膨大な数となり時間を要することになります。物体検出の高速化については、特徴抽出と識別処理を高速化することが必要となります。我々は識別処理の高速化に取り組んでいます。識別器の重みベクトルを分解することで、識別演算における内積演算の高速化と、近似計算過程における早期判定の導入により、高速な物体検出法を提案しています。
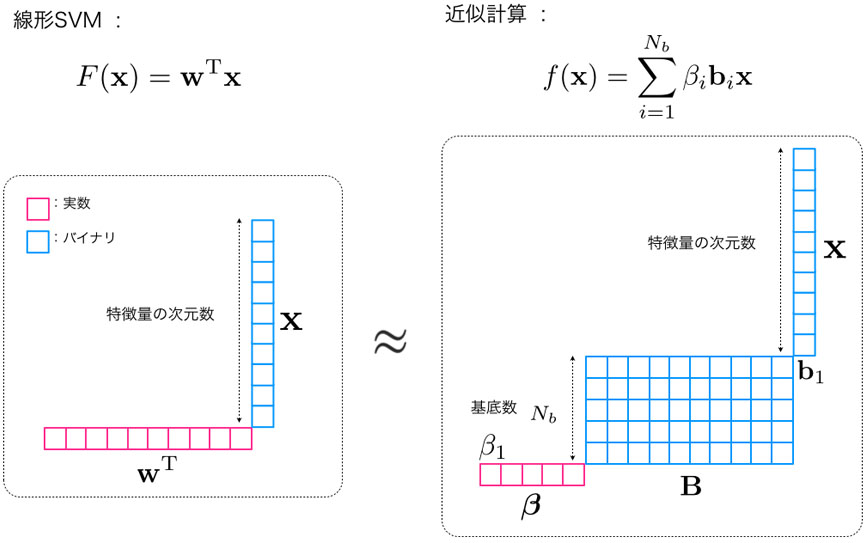
ベクトル分解法による識別器の高速化
線形SVMの重みベクトルをベクトル分解法により、実数のスケール係数ベクトルと基底バイナリコードに分解して近似します。このとき検出ウィンドウから抽出した特徴量を二値化しておくことで、内積計算における演算をバイナリ同士の演算に置き換えることができるため、高速な線形識別器の演算が可能となります。(HOGを二値化した特徴量についてはこちらをご覧下さい)
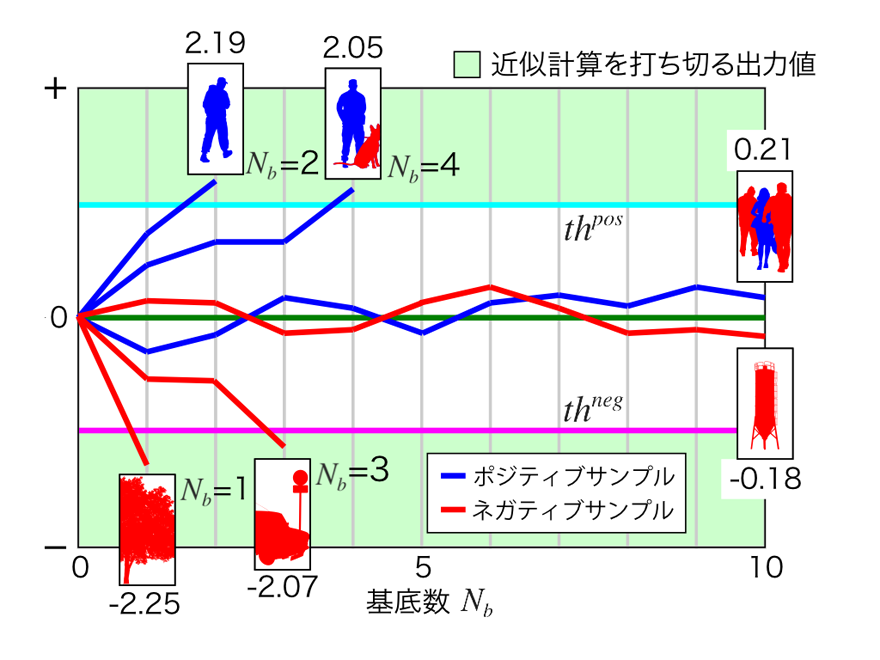
早期判定によるラスタスキャンの高速化
線形SVMの重みベクトルのように、高次元なベクトルを分解する場合、正確な近似計算には基底数を多く用いる必要があります。しかし、近似計算過程を観察すると、入力サンプルによって、少ない基底数で関数マージンから離れた値を出力することがあります。そこで、我々は近似計算過程で、関数マージン外の値となるサンプルの近似計算を打ち切り、早期判定を実現する手法を提案しています。これにより、線形SVMの性能を維持し、従来法と比べて約10倍高速な識別計算が可能となります。