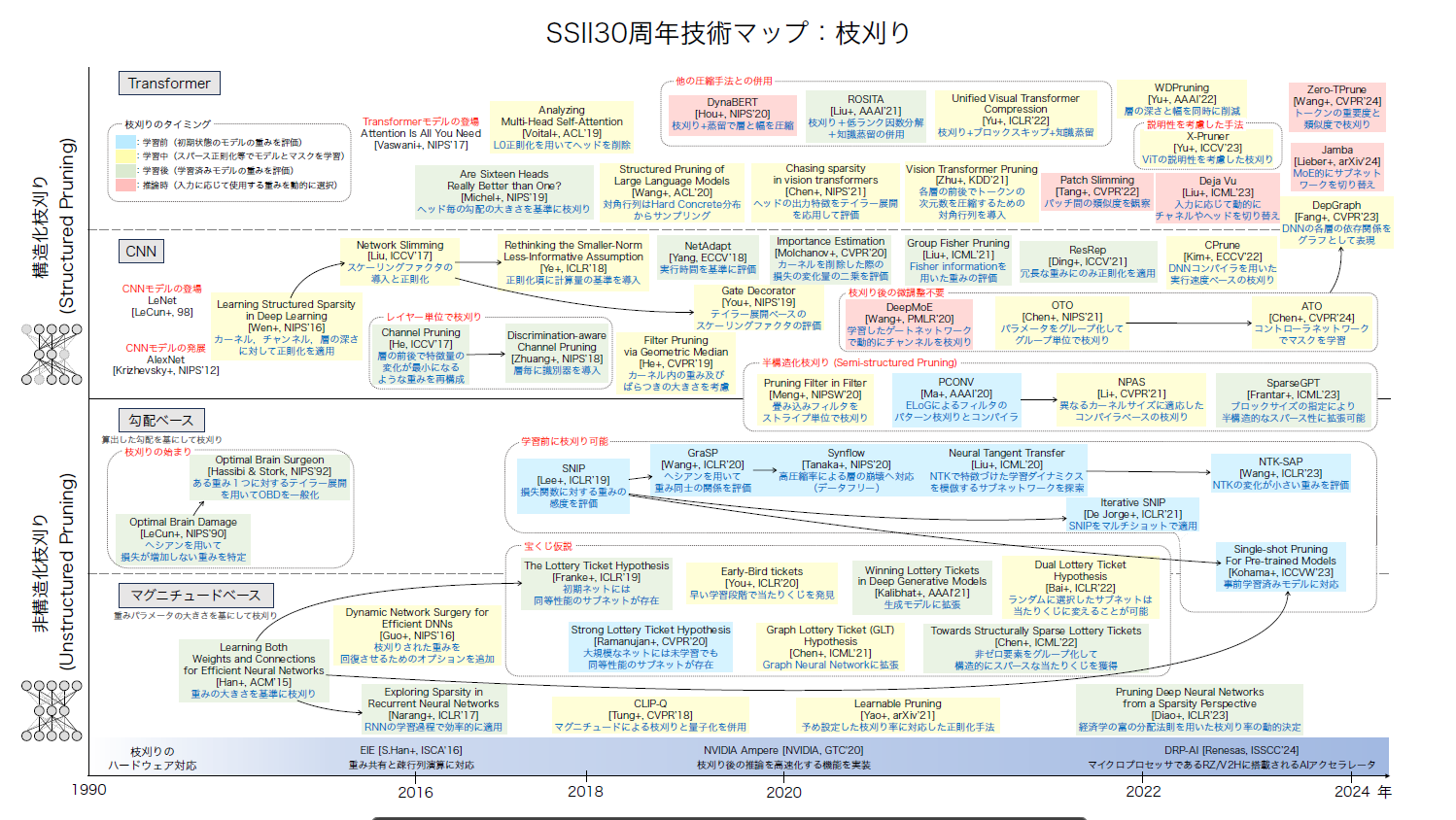
枝刈りによるモデルの軽量化
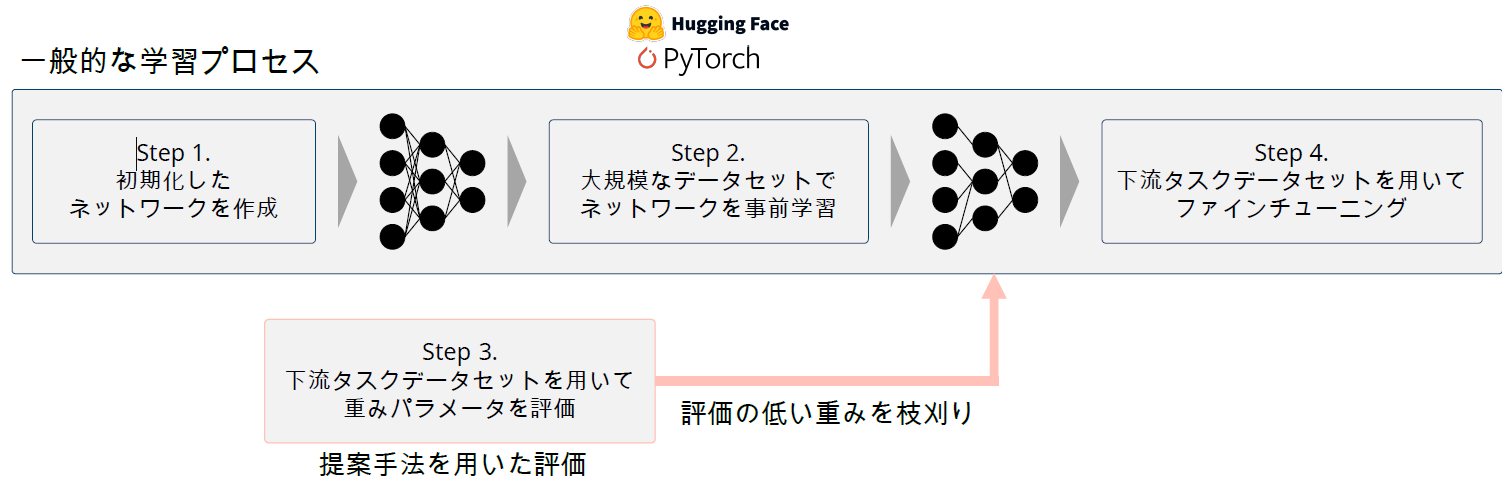
大規模な事前学習済みモデルは,下流タスクで適切なファインチューニングを行うことで様々な分野で高い性能を発揮することが知られています.また,これらの大規模事前学習済みモデルは,Hugging FaceやPytorchなどのライブラリから簡単に入手し,利用することができるようになっています.しかし,大規模な事前学習済みモデルは,ファインチューニングや推論に多くの計算リソースを必要とし,エッジデバイスでの実行や低レイテンシが求められる環境での利用に課題があります.そこで注目されるのがモデルの「枝刈り(Pruning)」技術です.
枝刈りとは,予測結果への寄与度が低いパラメータを特定し削除することで,モデルサイズを削減する手法です.
しかし,既存の枝刈り手法は,特定のタスクで学習済みのモデルを枝刈りしたり [Han+, ACM’15] ,モデルを学習しながら枝刈りを行う手法 [Wen+, NIPS’16] に関するものが大半を占めています.
モデルを学習する前に予測結果への寄与度が低いパラメータを予測して枝刈りする手法も提案されています [Lee+, ICLR’19] .
しかし,この枝刈り手法は初期状態のモデルをターゲットにしているため,大規模な事前学習済みモデルのパラメータを評価するにはいくつかの課題があります.
例えば,SNIPという枝刈り手法 [Lee+, ICLR’19] は,下流タスクの目的関数に対する各パラメータの勾配の大きさを基準に枝刈りするため,枝刈り後の下流タスクへの適応を大きく考慮しますが,事前学習で得た状態から離れる必要がない(勾配が小さい)パラメータを過小評価してしまいます.
これは,事前学習済みモデルを下流タスクに適応させる際に,事前学習で得たパラメータの近傍で最適化を促すことで汎化性能が向上するといった研究 [Tian+, CVPR’23] [Li+, ECCV’24] に反することになります.
そこで我々は,大規模事前学習済みモデルを下流タスクでファインチューニングする前に枝刈りするための研究に取り組んでいます.
SNIP-Mag:事前学習を考慮したシングルショット非構造枝刈り手法
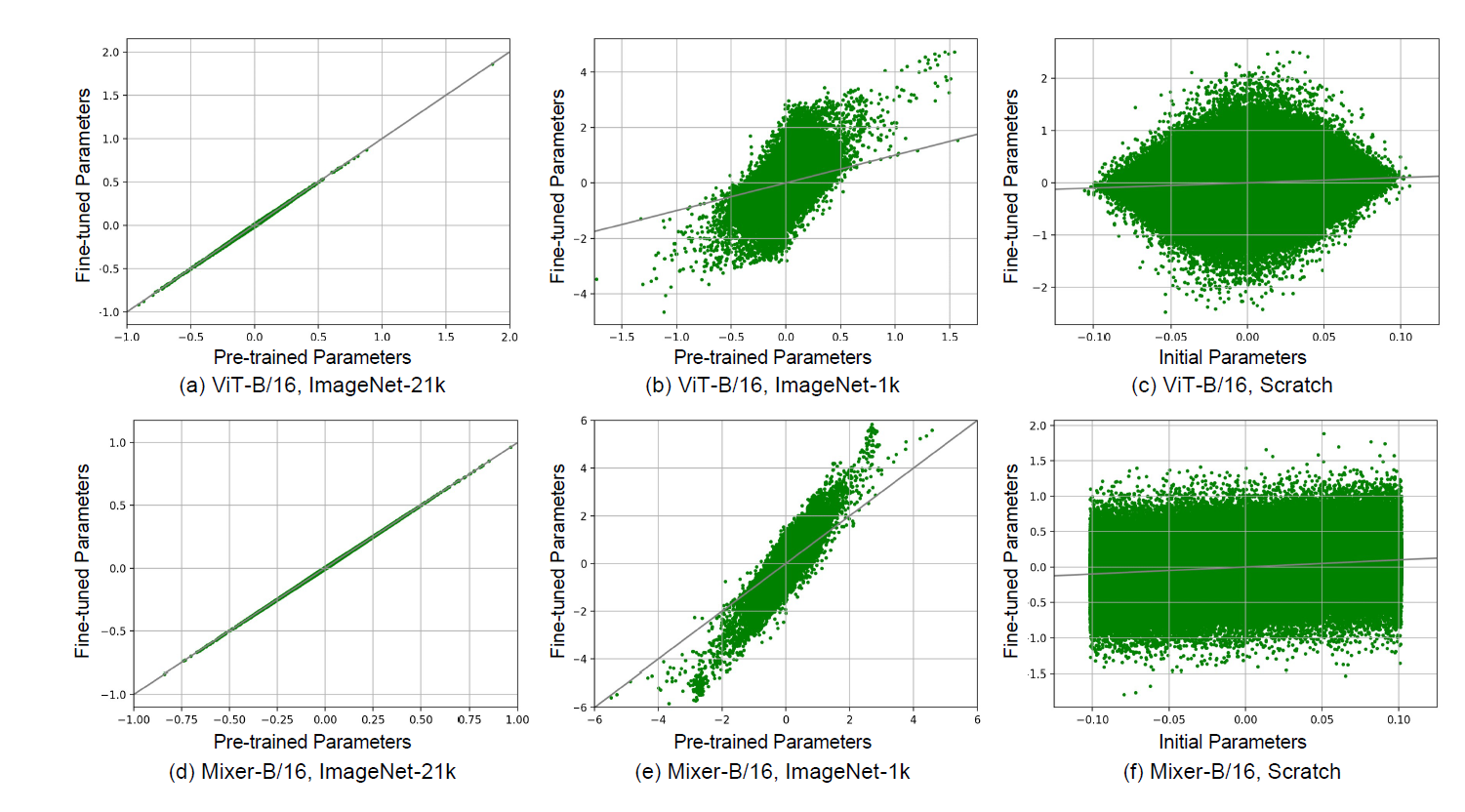
事前学習済みモデルのパラメータがどのように下流タスクに適応するかを詳細に調査するため、ViT-B/16やMixer-B/16などの事前学習済みモデルをCIFAR-10データセット上でファインチューニングする実験を行いました。この実験では、ImageNet-21kやImageNet-1kで事前学習したモデルと、スクラッチから学習したモデルのパラメータ変化を比較分析しました。図1の結果から、ImageNet-21kで事前学習したViT-B/16とMixer-B/16のパラメータは、CIFAR-10によるファインチューニング後もほぼ対角線上に分布しており、値がほとんど変化していないことが確認できました。一方、ImageNet-1kで事前学習したモデルや、スクラッチからのモデルでは、パラメータの変化がより大きいことがわかります。
この観察結果に基づき、事前学習済みモデルのパラメータは,下流タスクでほとんど変化しない傾向があります.この特性を活かし,勾配ベースの評価とパラメータの値の大きさを組み合わせた新しい枝刈り手法「SNIP-Mag」を開発しました.
SNIP-Magは従来の勾配ベースの枝刈り手法SNIPを拡張し,事前学習済みモデルのパラメータの大きさを直接評価に組み込んだ手法です.大規模なデータセットで十分に事前学習されたモデルのパラメータは,下流タスクへのファインチューニング前後でほとんど変化しないという観察に基づいています.この重要な知見を活かし,SNIP-Magではパラメータ評価の際に「目的関数に対する勾配の大きさ」と「パラメータ自体の大きさ」を組み合わせることで,既に収束している重要なパラメータと,下流タスクへの適応に更新が必要なパラメータの両方を適切に評価します.ハイパーパラメータαを導入することで,これら二つの評価基準のバランスを調整可能な設計となっています.
ReFer:事前学習済みモデルの特徴量の変化に着目した枝刈り手法
事前学習済みモデルは,その特徴表現の豊かさにより下流タスクで高い性能を発揮しますが,枝刈りによる圧縮時に出力特徴量の変化が大きいと,その性能が著しく低下することがあります.従来の勾配ベースの枝刈り手法(SNIP)や勾配フロー保持型の手法(GraSP)は,事前学習済みモデルにおいて期待通りの性能を発揮できないことが観察されています.これは事前学習済みモデルの最適解が下流タスクの初期点近傍に存在するという特性を考慮していないためです.
本研究では,枝刈りの前後で出力特徴量の分布を維持することを目的とした新しい枝刈りアルゴリズム「Retaining Feature Representation (ReFer)」を提案しています.ReFerの核心は,各層の出力特徴量のL1ノルムに対するパラメータの影響度を評価し,特徴量の変化を最小限に抑えるパラメータを優先的に残す点にあります.具体的には,下流タスクのミニバッチを用いて,各層の出力特徴量のL1ノルムに対する各パラメータの感度を計算し,感度の低いパラメータを優先的に枝刈りします.
AFR: Adaptive Feature Retaining for Single-shot Foresight Pruning
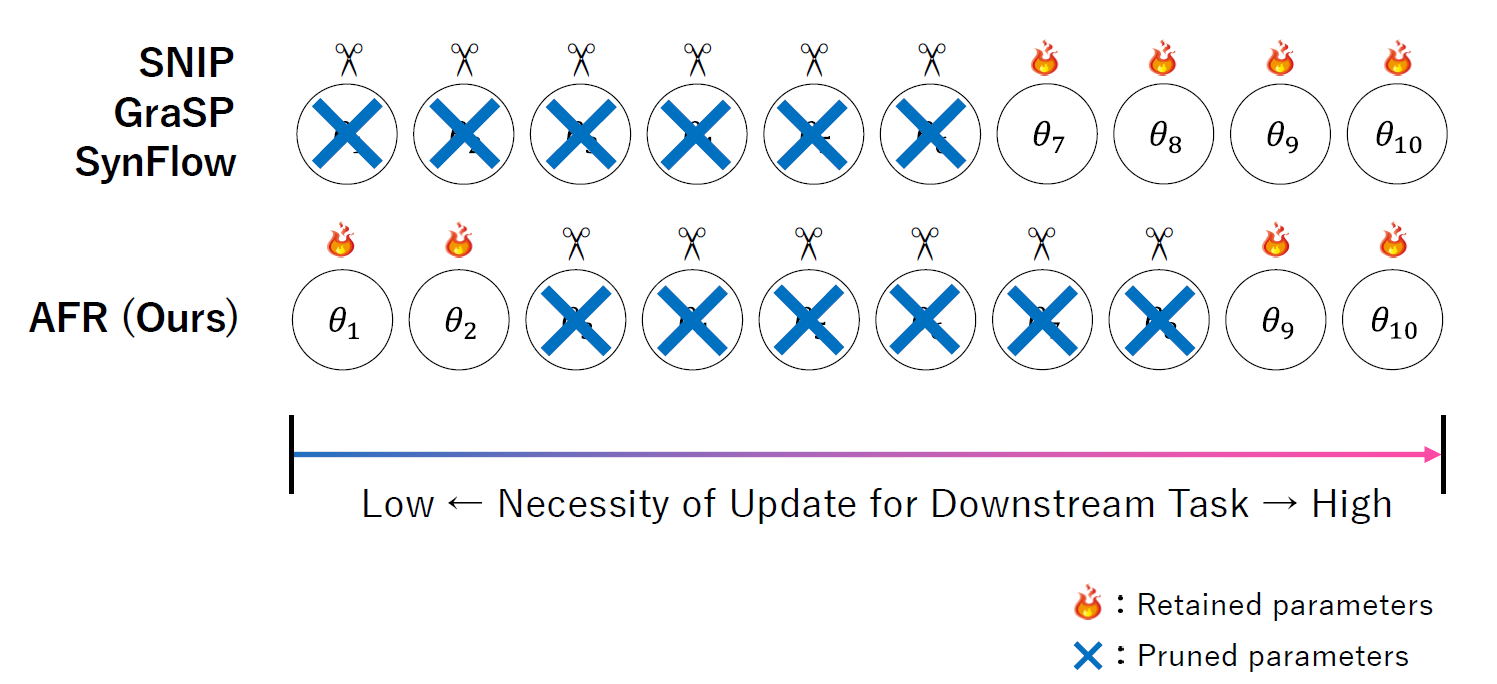
SNIP-MagやReFerは,一定の性能を発揮する一方で,いくつかの問題を抱えています.
SNIP-Magはパラメータの評価にハイパーパラメータを必要とします.ReFerは特徴量のL1ノルムを維持しますが,L1ノルムはベクトルの大きさのみに着目するため,それを事前学習で得た知識として定義するには不十分です.また,事前学習で得た知識の維持のみを目的にするため,下流タスクが難しくなった場合に極端に性能が低下する可能性があります.
本研究では,事前学習済みモデルの特徴表現を維持しながら下流タスクへの適応も考慮する新しい枝刈りアルゴリズムを提案しています.この手法では,事前学習済みモデルの各層が出力する特徴量に対して特異値分解を適用し,その特異値を維持します.具体的には,パラメータに摂動を与えた際の特異値への影響から重要なパラメータを特定します.実際に,特徴量に対する特異値によりモデルの特徴表現を評価している研究もおこなわれています [Jing+, ICLR’22].さらに,下流タスクの目的関数に対する勾配を同時に考慮することで,事前学習で獲得した知識の保持と下流タスクへの適応のバランスを取ります.このように,特異値を用いた特徴空間評価と勾配情報を組み合わせることで,枝刈り後のモデルが事前学習で得た知識を維持しつつ,下流タスクへの適応の考慮を両立することが可能です.
評価実験
一般物体認識データセットでの評価
提案手法の有効性を様々な事前学習条件とデータセットの組み合わせで評価するために、ImageNet-1k、ImageNet-21k、自己教師あり学習(DINO)で事前学習されたVision TransformerのBaseモデルを使用し、CIFAR-10、CIFAR-100、Tiny-ImageNetの3つのデータセットで実験を行いました。この実験では、提案手法(AFR、SNIP-Mag、ReFer)が異なる枝刈り率(90%、95%、98%)において、従来手法(Magnitude、SNIP、GraSP、SynFlow)と比較してどの程度精度を維持できるかを検証しました。
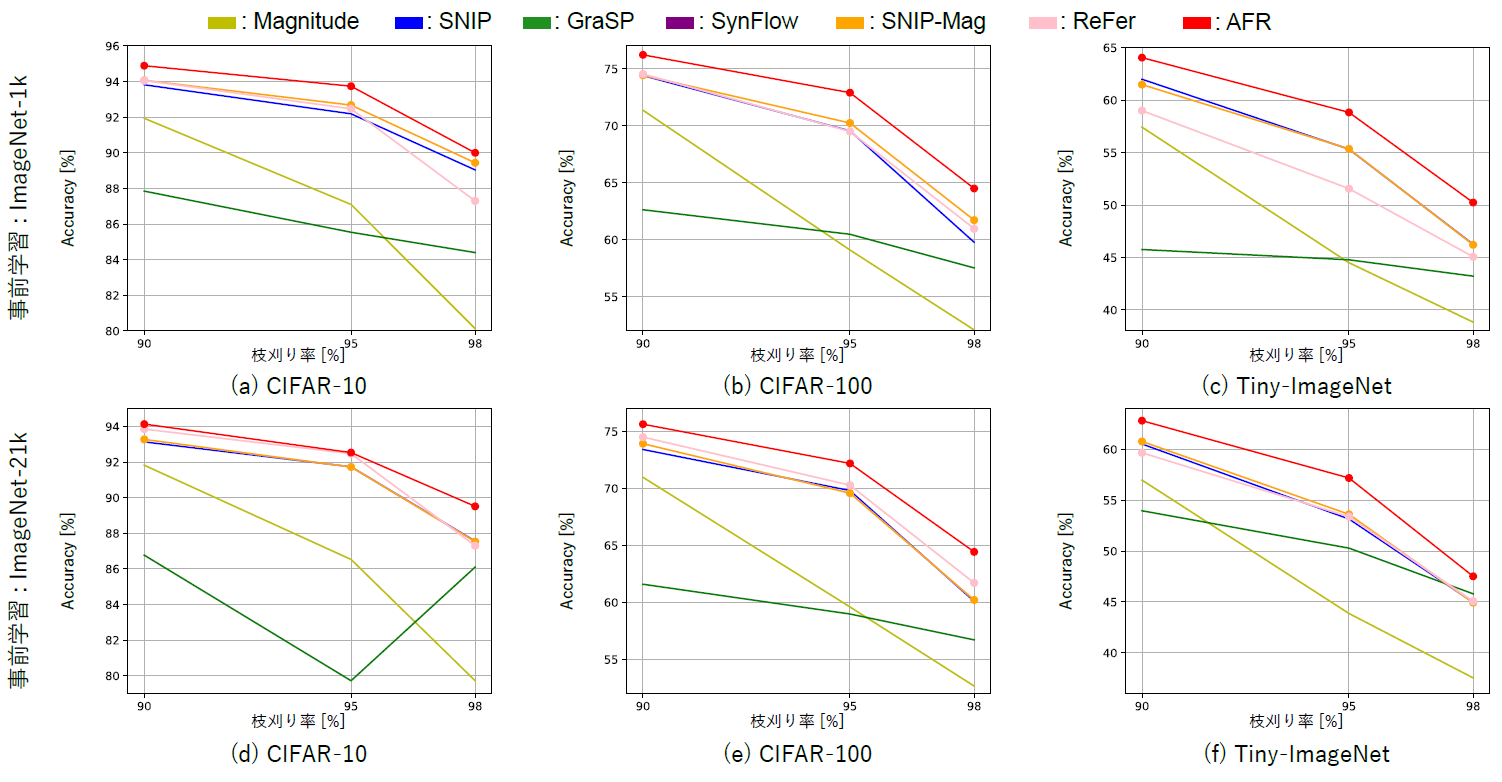
実験では,異なる枝刈り率(90%,95%,98%)において,提案手法(AFR,SNIP-Mag,ReFer)と従来手法(Magnitude,SNIP,GraSP,SynFlow)を比較しました.グラフに示されている通り,提案手法はほとんどの事前学習方法およびデータセットの組み合わせにおいて,従来手法と比較して高い分類精度を達成しました.
これらの結果から,高いスパース率においてもモデルの性能を効果的に維持できることが確認されました.中でもAFRは,事前学習で得た知識を最もよく保持しながら下流タスクへの適応も実現しており,全体的に最も優れた結果を示しています.
特定物体認識データセットでの評価
より現実的な問題を評価するために,特定物体認識タスクでも10個のデータセットを用いて評価を行いました.
特定物体認識タスクとは,特定の物体やカテゴリに焦点を当てたタスクです.事前学習には多様なカテゴリが含まれるImageNetデータセットを用いますが,特定物体認識データセットであるPetsでは,犬や猫といったカテゴリではなく,その種類を特定したり,ISICでは,皮膚の疾患の画像分類を目的とします.そのため,事前学習で使用したデータと下流タスク間でデータの分布に若干の差があると考えられます.

一般物体認識データセットでの評価において最も高い性能を示した従来手法であるSNIPを従来手法の代表として選択しました.
Vision-TransformerのBaseモデルをImageNet-1kで事前学習し,80%の枝刈り率で各手法を適用した結果を比較しました.10個の特定物体認識データセット(Diseases,EuroSAT,Caltech-101,ISIC,Pets,ChestX,DTD,Cars,SUN397,Aircraft)において,提案手法は従来手法よりも概ね高い精度を示しました.
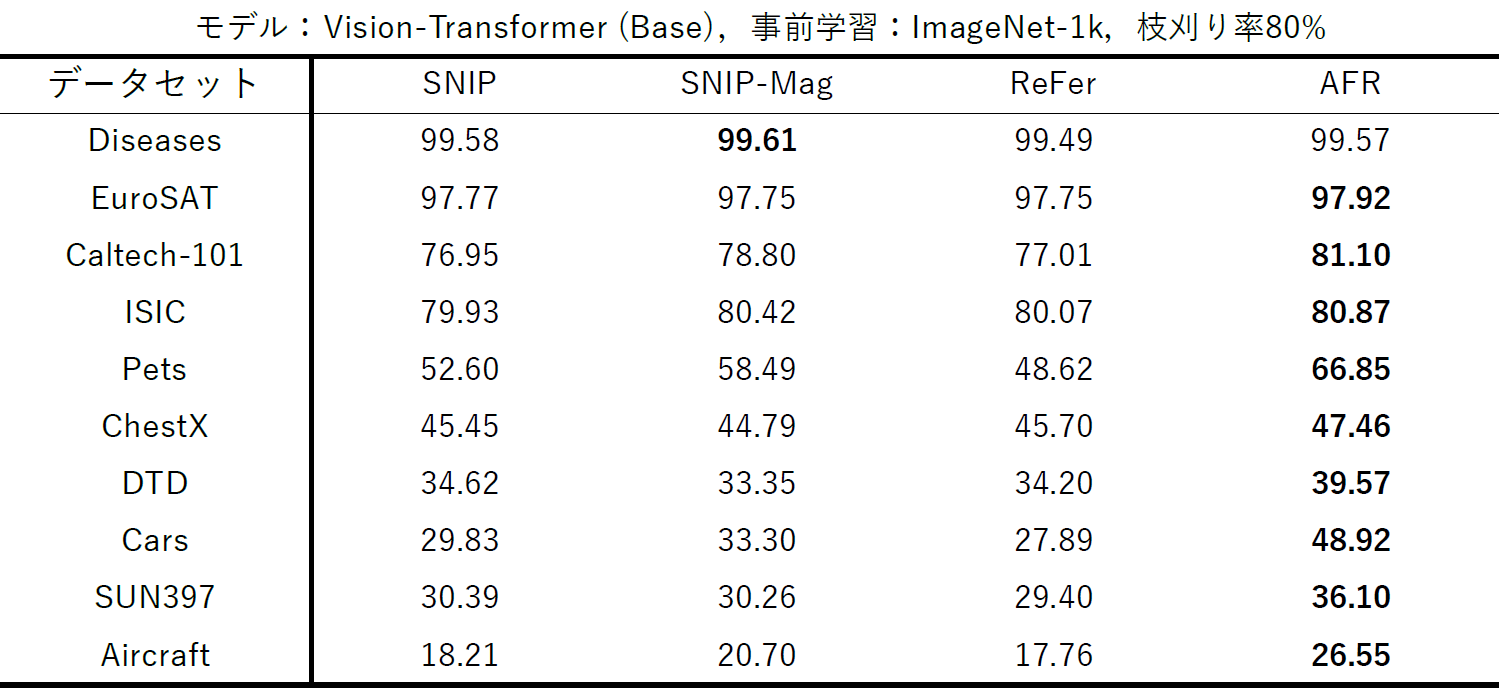
特に注目すべき点として,ドメインギャップが大きいデータセットを使用している中で提案手法,特にAFRの優位性が顕著になりました.例えば,Petsデータセットでは,AFRは66.85%の精度を達成し,SNIP-Magの58.49%,ReFerの48.62%と比較して大幅な向上を示しています.また,Carsデータセットでは,AFRは48.92%の精度でSNIP-Magの33.30%,ReFerの27.89%より大きく上回る結果となっています.
このように,提案手法は単に分類精度を維持するだけでなく,事前学習と下流タスク間のドメインギャップが大きい場合でも高い性能を発揮できることが確認されました.これは実用的なシナリオにおいて,提案手法の優位性と汎用性を示す重要な結果です.中でもAFRは,事前学習の知識維持と下流タスク適応のバランスを最も効果的に実現しており,特に難しいドメイン転移タスクで顕著な性能向上を示しています.